レッスン2から4は、Research環境で行います。
Research環境を利用するときには、新しいノートブックを作成 して下さい。
1.3. データを探す¶
Researchは、価格、出来高、およびリターンを照会するためのユーティリティ関数を提供します。 データは、2002年から今日現在までの8000株以上の米国株式データです。 関数は、資産(または資産のリスト)、開始日、終了日を引数として受け取り、日付をindexに持つ、pandasの Series (もしくは DataFrame)を返します。
ここで、期間を指定して、AAPLのリターンを returns 関数を使って照会してみましょう。
# Research環境用関数
from quantopian.research import returns, symbols
# 時間範囲を指定
period_start = '2014-01-01'
period_end = '2014-12-31'
# 上記の時間範囲で、AAPLのリターンデータを照会する
aapl_returns = returns(
assets=symbols('AAPL'),
start=period_start,
end=period_end,
)
# 最初の10行のみ表示
aapl_returns.head(10)
2014-01-02 00:00:00+00:00 -0.014137
2014-01-03 00:00:00+00:00 -0.022027
2014-01-06 00:00:00+00:00 0.005376
2014-01-07 00:00:00+00:00 -0.007200
2014-01-08 00:00:00+00:00 0.006406
2014-01-09 00:00:00+00:00 -0.012861
2014-01-10 00:00:00+00:00 -0.006674
2014-01-13 00:00:00+00:00 0.005043
2014-01-14 00:00:00+00:00 0.020123
2014-01-15 00:00:00+00:00 0.020079
Freq: C, Name: Equity(24 [AAPL]), dtype: float64
1.3.1. さまざまなデータ¶
Quantopianには、価格や出来高のデータだけでなく、企業のファンダメンタルズやセンチメント分析、マクロ経済指標など様々なデータセットが用意されています。データセットは、全部で50以上用意されており、詳細については、Quantopianの Data Reference で確認できます。
このチュートリアルでは、センチメントデータを使って株式を選び、取引を評価するところまで扱います。 今回は、センチメントデータとして、PsychSignalの StockTwits Trader Mood データセットを使います。このPsychSignalのデータセットは、Stocktwitsという株式専門SNSに投稿されたメッセージの総体的なセンチメントに基づいて、日次で銘柄ごとにブル(強気)とベア(弱気)のスコアを割り当てたものです。
ではまず、stocktwits データセットのメッセージの総量とセンチメントスコア(ブルからベアを引いたもの)の列を見ていきましょう。
データを照会するには、QuantopianのPipeline APIを使います。
Pipeline APIは、今後Research環境でデータを照会したり分析したりする時に何度も使うことになります。
詳しくは次のレッスンや、Pipeline専用のチュートリアル で学ぶことができます。
今のところ知っておく必要があるのは、以下のコードがdata pipelineを使用して stocktwits を照会してデータを返し、AAPLの結果をプロットしているということだけです。
# Pipeline imports
from quantopian.research import run_pipeline
from quantopian.pipeline import Pipeline
from quantopian.pipeline.factors import Returns
from quantopian.pipeline.data.psychsignal import stocktwits
# Pipeline 定義
def make_pipeline():
returns = Returns(window_length=2)
sentiment = stocktwits.bull_minus_bear.latest
msg_volume = stocktwits.total_scanned_messages.latest
return Pipeline(
columns={
'daily_returns': returns,
'sentiment': sentiment,
'msg_volume': msg_volume,
},
)
# Pipeline 実行
data_output = run_pipeline(
make_pipeline(),
start_date=period_start,
end_date=period_end
)
# AAPLのデータだけを取得
aapl_output = data_output.xs(
symbols('AAPL'),
level=1
)
# 描画
aapl_output.plot(subplots=True);
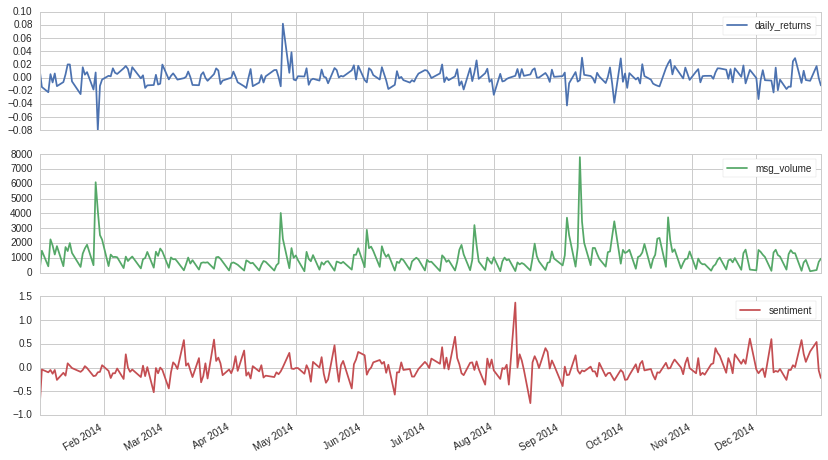
データセットの中味を検討するときには、データセットと株価の動きを見比べて、何かパターンがないか探して見てください。そうして見つけたパターンが、取引ストラテジーの基礎になるかもしれません。
上記の例では、株価の日々のリターン(収益)のスパイク(急激な変化)と stocktwits のメッセージ総量のスパイクが、いくつか同じタイミングで起きていることが見て取れますし、リターンのスパイクとAAPLのセンチメントスコアの方向がマッチしている様子もいくつか確認できます。
こうして見ると、充分に使えそうな面白いデータセットのようですので、さらにしっかりと統計的に分析して、うまく行くかどうか検証してみましょう。
次のレッスンでは、Pipeline APIについて詳しく説明します。